Query Time: Day 4, 10:50:35
Question: Outside of mealtimes, what was the last group activity we did in the projector room?
A. Presenting slides B. Learning dance C. Chatting D. Preparing food E. Watching movies
Query Time: Day 4, 13:27:25
Question: What other food have we eaten on this table before?
A. BBQ, pizza B. Hotpot, pizza, KFC C. Hotpot, pizza D. Pizza, KFC










Query Time: Day 7, 13:00:00
Question: Where do we usually have meals together?
A. The table outside B. Gingham table C. The orange table D. My desk E. In restaurant
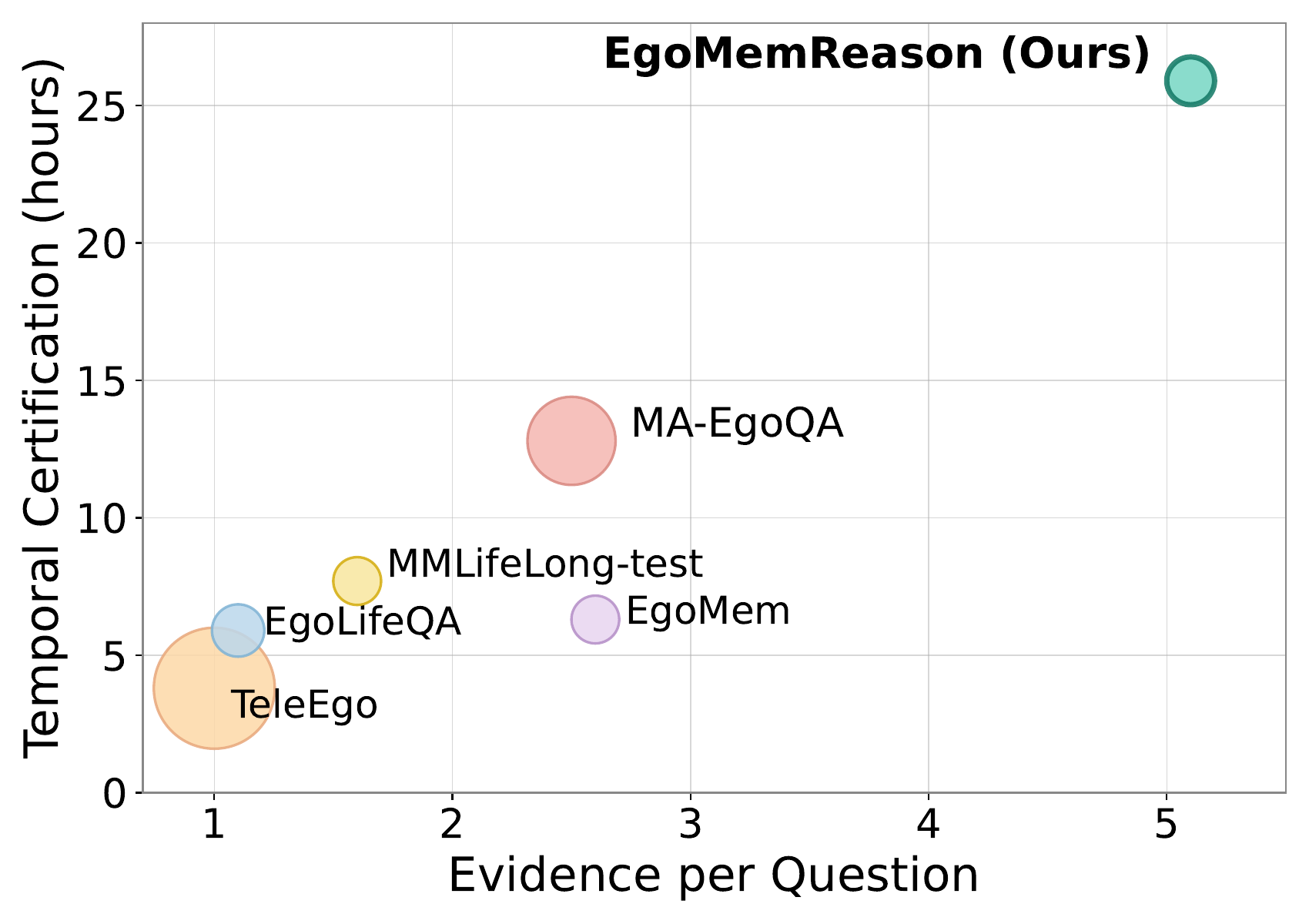
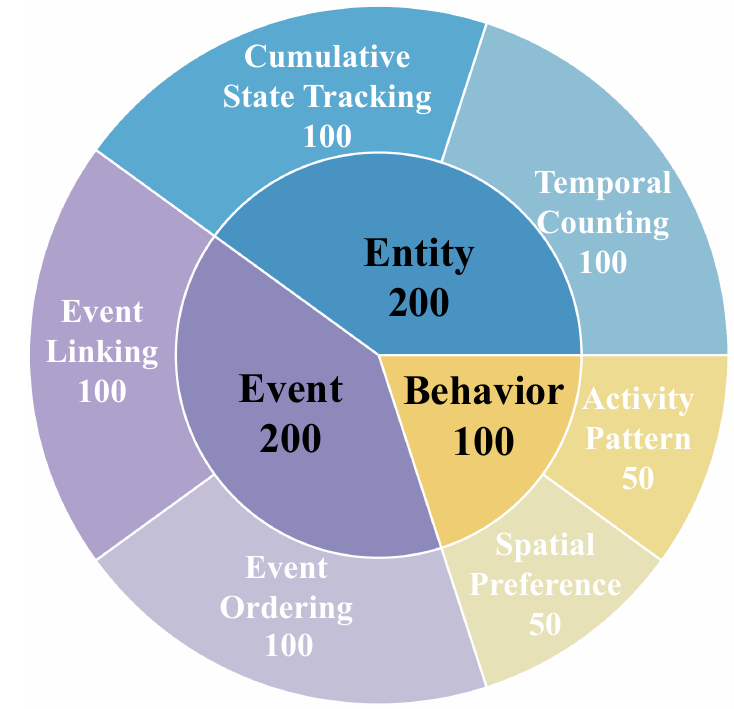
Figure 1: Illustration of EgoMemReason for week-long egocentric video memory. Given a query at a specific time, answering requires retrieving and aggregating evidence from multiple temporally distant observations across days. We categorize memory into three types: entity memory (tracking persistent objects and states), event memory (ordering and linking events), and behavior memory (inferring patterns). Together they support multi-type, long-range, multi-evidence reasoning.